爬取南京房价 爬虫系列
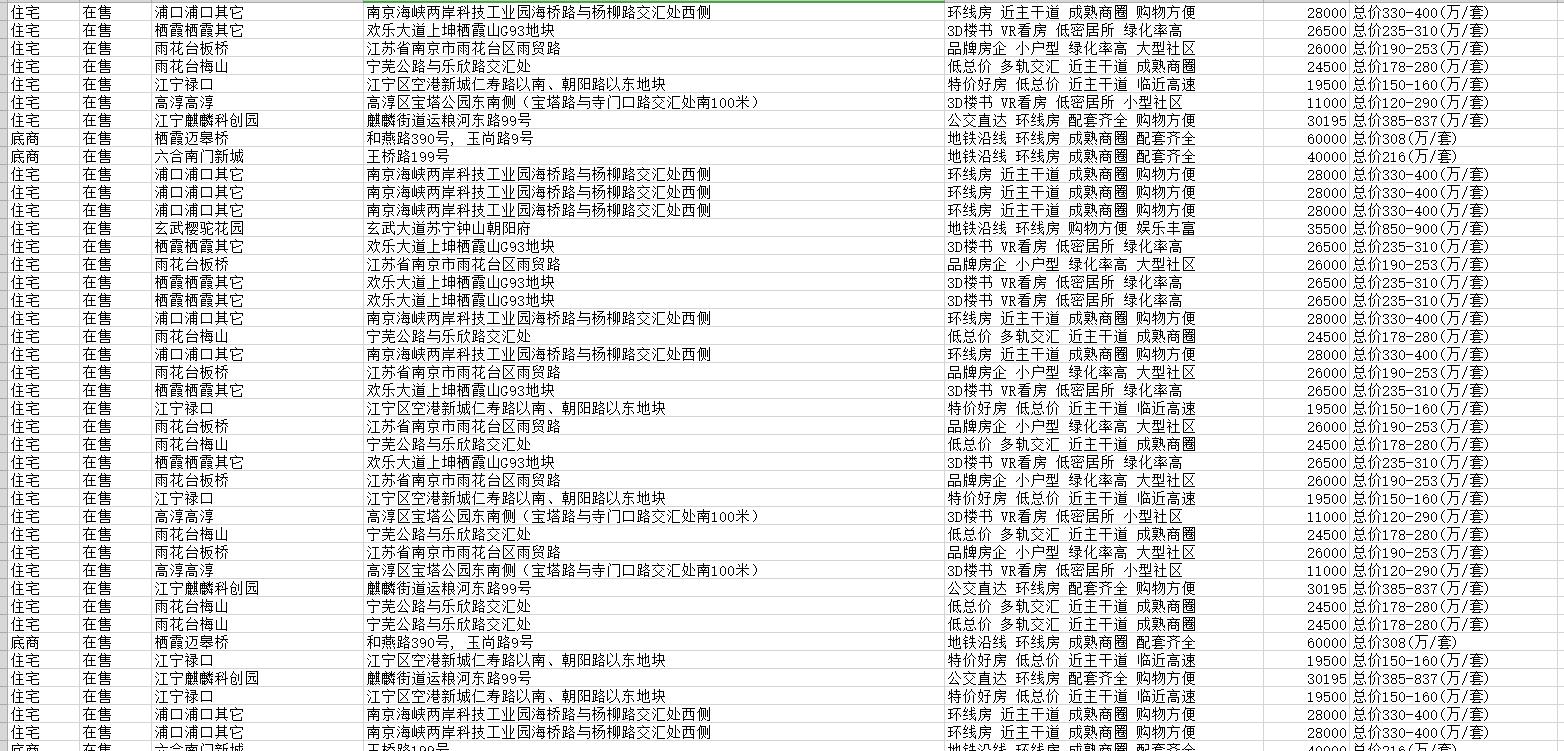
1 基本概念网络爬虫(Crawler):又称网络蜘蛛,或者网络机器人(Robots). 它是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。换句话来说,它可以根据网页的链接地址自动获取网页内容。如果把互联网比做一个大蜘蛛网,它里面有许许多多的网页,网络蜘蛛可以获取所有网页的内容。爬虫是一个模拟人类请求网站行为, 并批量下载网站资源的一种程序或自动化脚本。爬虫:使用任何技术手段,批量获取网站信息的一种方式。关键在于批量。反爬虫:使用任何技术手段,阻止别人批量获取自己网站信息的一种方式。关键也在于批量。误伤:在反爬虫的过程中,错误的将普通用户识别为爬虫。误伤率高的反爬虫策略,效果再好也不能...